중앙값과 순서 통계량
Updated:
시작하면서
이번 개념은 중앙값과 순서 통계량(Medians and Order Statistics) 카테고리이다. 공부는 Introduction To Algorithms(3rd)을 번역하면서 진행하려고 한다.
Medians and Order Statistics
n개의 요소 집합의 i차 통계량은 i번째로 작은 요소이다. 예를 들어, 요소 집합의 최소값은 1차 통계랑(i = 1)이고, 최대값은 n차 통계량 (i = n)이다. 비공식적으로 중앙값은 세트의 “halfway point” 이다.
n이 홀수이면 중앙값은 고유하며, i = (n + 1 )/2에서 발생한다. n이 짝수이면, i = n/2 와 i = n/2 + 1에서 발생하는 2개의 중앙값이 존재한다.
따라서 n의 parity와 무관하게 중앙 값은 i = (n + 1)/2(의 하한) 및 i = (n+1)/2(의 상한)에서 발생한다. 그러나 이 텍스트의 편의를 위해 “중앙”이라는 문구를 일관되게 사용해 하위 중앙값을 나타내자.
이 장에서는 n개의 고유 숫자 세트에서 i차 통계량을 선택하는 문제를 해결한다. 편의상 세트에 고유 번호가 있다고 가정하지만 사실상 우리가 하는 모든 작업은 세트에 반복되는 값이 포함된 상황까지 확장된다. 다음과 같이 선택 문제를 공식적으로 지정한다.
- Input : n개의 고유한 숫자 A와 정수 i, (1 <= i <= n)
- output : 정확하게 A의 i-1개의 다른 원소들 보다 더 큰 A에 속한 원소 x
우리는 힙 정렬 또는 병합 정렬을 사용해 숫자를 정렬 한 다음, 출력 배열에서 i번째 요소를 간단히 색인 할 수 있기 때문에 선택 문제를 O(nlogn) 시간으로 해결할 수 있다. 이 장에서는 더 빠른 알고리즘을 제시한다.
섹션 1에서는 set of elements의 최소값과 최대값을 선택하는 문제를 살펴본다. 더 흥미로운 것은 일반적인 선택 문제인데, 다음 두 섹션에서 조사한다.
섹션 2는 별개의 요소를 가정해 O(n) 예상 실행 시간을 달성하는 실용적인 무작위 알고리즘을 분석한다.
섹션 3에는 최악의 경우 O(n) 런닝 시간을 달성하는 보다 이론적인 알고리즘이 포함되어있다.
1) Minimum and maximum
n개의 요소 집합의 최소값을 결정하기 위해 얼마나 많은 비교가 필요한가? 우리는 n - 1 비교의 상한을 쉽게 얻을 수 있다:
세트의 각 요소를 차례로 검사하고, 지금까지 본 가장 작은 요소를 추적한다. 다음 절차에서 우리는 세트가 배열 A에 있다고 가정하고, 이 때 배열 A의 길이는 n이다.
MINIMUM(A)
min = A[1]
for i = 2 to A.length
if min > A[i]
min = A[i]
return min
물론 우리는 n-1의 비교 횟수로 최대값을 찾을 수 있다.
이것이 우리가 할 수 있는 최선인가? 그렇다. 최소값을 결정하는 문제에 대해 n-1 비교의 하한을 얻을 수 있기 때문이다. 요소들 사이에서 최소값을 토너먼트로 결정하는 알고리즘을 생각해라. 각 비교는 토너먼트에서 두 요소 중 작은 요소가 이기는 경기이다. 우승자를 제외한 모든 요소가 하나 이상의 경기에서 패배해야 한다는 것을 관찰해 최소값을 결정하기 위해 n-1 비교가 필요하다고 결론 내렸다.
따라서 MINIMUM 알고리즘은 수행된 비교 횟수와 관련해서 최적의 알고리즘이다.
Simultaneous minimum and maximum (동시 최소 및 최대)
일부 어플리케이션에서 우리는 n개 요소 집합의 최소값과 최대값을 모두 찾아야한다. 예를 들어, 그래픽 프로그램은 직사각형 디스플레이 화면 또는 기타 그래픽 출력 장치에 맞게 (x, y) 데이터 세트를 스케일링해야 할 수도 있다. 그렇게 하려면 프로그램이 먼저 각 좌표의 최소값과 최대값을 결정해야한다.
이 시점에서 n 비교를 사용해 n 요소의 최소 값과 최대값을 모두 결정하는 방법이 분명해야한다. 이는 무조건 최적이다:
총 2n-2 번의 비교를 위해 각각 n-1 비교를 사용해 최소값과 최대값을 독립적으로 찾기만 하면 된다.
실제로 최대 3 (n/2)(의 하한) 비교를 사용해 최소값과 최대값을 모두 찾을 수 있다. 우리는 지금까지 본 최소 및 최대 요소를 모두 유지함으로써 그렇게 한다. 요소당 2개의 비교 비용으로 입력의 각 요소를 현재 최소값과 최대값과 비교해 처리하는 대신 요소를 쌍으로 처리한다. 입력의 요소 쌍을 먼저 서로 비교 한 다음 두 요소마다 3번의 비교 비용으로 현재 최소값과 더 큰 값을 현재 최대값과 비교한다.
현재 최소값과 최대값의 초기값을 설정하는 방법은 n이 홀수인지 짝수인지에 따라 다르다. n이 홀수이면 최소값과 최대값을 첫 번째 요소의 값으로 설정한 다음 나머지 요소를 쌍으로 처리한다. n이 짝수이면 처음 두 요소에 대해 1 비교를 수행해 최소값과 최대값의 초기값을 결정한 다음 홀수 n의 경우와 같이 나머지 요소를 쌍으로 처리한다.
총 비교 횟수를 분석해보자. n이 홀수이면 3 (n/2)(의 하한) 비교를 수행한다. n이 짝수이면 1개의 초기 비교와 3(n-2)/2 비교를 수행해 총 3n/2 - 2가 수행된다. 따라서 두 경우 모두 총 비교 횟수는 3(n-2)(의 하한)이다.
정리하자면 다음과 같다.
-
n이 홀수이면 1번째 값을 최대&최소값으로 놓는다. n이 짝수이면 1번째와 2번째 값을 비교해서 최대&최소값을 정한다.
-
다음 인덱스부터는 2개의 값을 짝지어서 2개의 값 중에 어느 것이 더 크고 작은지(1번 비교), 큰 값은 최대값과 비교하고(1번 비교), 작은 값을 최소값과 비교한다(1번 비교).
-
값의 수가 n이라고 했을 때 이를 마지막까지 진행하면 n/2 번만큼 2를 진행하게 되고, 짝수 일 때에는 1번을 진행해야 하므로 각각
- 짝수 : 3(n/2) + 2
- 홀수 : 3(n/2)
만큼 비교를 진행하게 된다.
2) Selection in expected linear time
일반적인 selection 문제는 최소값을 찾는 단순한 문제보다 어렵게 보인다. 그러나 놀랍게도 두 문제에 대한 점근적 실행 시간은 같다(O(n)). 이 섹션에서는 선택 문제에 대한 분할 및 정복 알고리즘을 제시한다.
RANDOMIZED-SELECT 알고리즘은 퀵 정렬을 모델로 한다. 퀵 정렬과 마찬가지로 입력 배열을 재귀적으로 분할한다. 그러나 RANDMOIZED-SELECT는 파티션의 양쪽을 재귀적으로 처리하는 퀵 정렬과 달리 파티션의 한쪽에서만 작동한다. 이 차이는 분석에 나타난다:
퀵 정렬의 예상 실행 시간은 O(nlogn) 이지만, RANDOMIZED-SELECT의 예상 실행 시간은 O(n)이며 요소가 서로 다르다고 가정한다.
RANDOMIZED-SELECT는 RANDOMIZED-PARTITION 절차를 사용한다. 따라서 RANDMOIZED-QUICKSORT와 같이 동작은 난수 생성기의 출력에 의해 부분적으로 결정되므로 무작위 알고리즘이다. RANDOMIZED-SELECDT에 대한 다음 코드는 배열 A[p..r]의 가장 작은 i번째 요소를 반환한다.
RANDOMIZED-SELECT(A, p, r, i)
if p == r
return A[p]
q = RANDOMIZED-PARTITION(A, p, r)
k = q - p + 1
if i == k // pivot value가 답인 경우
return A[q]
else if i < k
return RANDOMIZED-SELECT(A, p, q - 1, i)
else
return RANDOMIZED-SELECDT(A, q + 1, r, i - k)
RANDOMIZED-PARTITION(A, p ,r)
i = RANDOM(p,r)
exchange A[r] with A[i]
return PARTITION(A, p ,r)
PARTITION(A, p, r)
x = A[r]
i = p-1
for j = p to r-1
if A[j] <= x
i = i+1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1
RANDOMIZED-SELECT 절차는 다음과 같이 작동한다.
먼저 Line 1은 재귀의 기본 사례를 확인한다. 여기서 하위 배열 A[p..r]은 하나의 요소로만 구성된다. 이 경우 i는 1과 같아야하며, 2행의 A[p]를 i번째로 작은 요소로 간단히 반환한다. –> (배열의 크기가 1인 경우)
Line 1을 하면 Line 3에서 RANDOMIZED-PARTITION을 호출하게 되어 배열 A가 두 개의 서브 어레이로 배열된다. 서브 어레이는 A[p..q-1] 및 A[q + 1..r]로 분할된다. A[p..q-1]의 원소는 A[q]보다 작거나 같으며, A[q+1..r]의 각 원소보다 작다. (퀵 정렬에서와 같이 여기서도 A[q]를 피벗 요소라고 한다)
Line 4는 서브 어레이 A[p..q]의 요소 개수 k, 즉 파티션의 아래 쪽에 있는 요소 수에 피벗 요소의 인덱스를 더한 값을 계산한다.
Line 5는 A[q]가 i번째로 작은 요소인지 확인한다. 맞다면 바로 A[q]를 반환한다. 그렇지 않으면 알고리즘은 두 하위 배열 A[p..q-1] 및 A[q+1..r] 중 가장 작은 요소가 어디에 있는지 다시 진행한다. i < k 이면 원하는 요소가 파티션의 아래쪽에 있고, Line 8은 하위 배열에서 해당 요소를 재귀적으로 선택한다. 그러나 i > k 이면 파티션의 상위 배열에서 요소를 재귀적으로 선택한다.
우리는 이미 A[p..r]의 i번째 가장 작은 요소보다 작은 k 값을 알고 있기 때문에, 즉 A[p..q]의 요소는 원하는 요소가 (i-k) 번째로 작은 요소이다.
RANDOMIZED-SELECT의 최악의 경우 실행 시간은 O(n^2)이다. 최소값을 찾을 때 항상 운이 좋지 않고, 가장 큰 나머지 요소를 파티셔닝했을 때 이다. 우리는 알고리즘이 예상되는 선형 실행 시간을 가짐을 알 수 있으며, 랜덤화되기 때문에 특정 입력이 최악의 경우를 유발하지는 않는다.
RANDOMIZED-SELECT의 예상 실행 시간을 분석하려면 n개 요소의 입력 배열 A[p..r]에서 실행 시간을 T(n)으로 표시되는 임의의 변수로 만들고, 다음과 같이 E[T(n)]으로 상한을 얻는다. RANDOMIZED-PARTITION 절차는 모든 요소를 피벗으로 반환 할 가능성이 있다. 따라서 1<=k<=n 이 되도록 각 k에 대해 서브 어레이 A[p..q]는 확률 1/n의 k요소를 갖는다. k = 1, 2…, n,의 경우 지표 랜덤 변수 Xk를 다음과 같이 정의한다.
- Xk = I {하위 배열 A[p..q]에는 정확히 k개의 요소가 있다.}
요소가 서로 다르다고 가정하면
- E[Xk] = 1/n (9.1)
상계를 정하기 위해서 배열 분할시 항상 더 많은 요소를 가진 쪽에 i번째 요소가 존재한다고 가정한다. RANDOMIZED-SELECT 호출시, 확률 지표 변수 Xk는 k값으로 정해진 하나의 값에 대해 1을 가지고, 나머지 모든 값에는 0을 가진다. Xk = 1일 때, 두 개의 부분 배열은 k-1과 n-k 크기를 가진다.
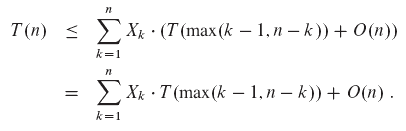
기대값을 양쪽에 취하면 다음을 가진다
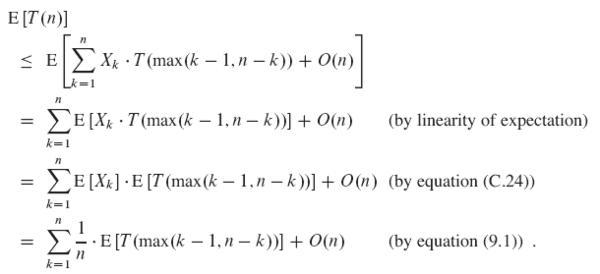
식 (C.24) : E[X1X2…Xn] = E[X1]E[X2]…E[Xn] 일 때 T(max(k-1, n-k))를 분석해보자.
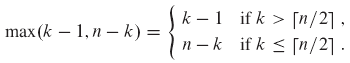
n이 짝수면 합에서 T([n/2])부터 T(n-1)까지 나오는 각 항은 정확히 두 번씩 나타난다. n이 홀수이면 각 항이 두 번씩 나오다가 마지막에 T([n/2])이 추가로 한 번 나타난다. 따라서 다음 식을 갖는다.
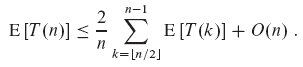
치환법으로 E[T(n)] = O(n)임을 증명한다.
- 가정
- E[T(n)] <= cn
- T(n) = O(1)
- O(n) = an
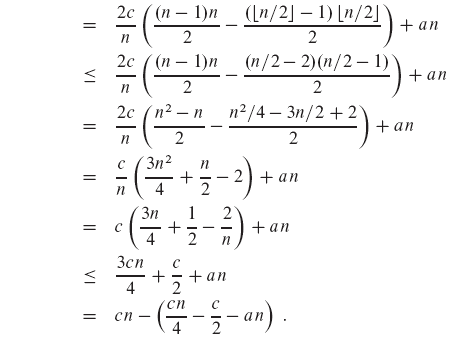
충분히 큰 n에 대해 마지막 표현식은 최대 cn임을 보여야한다. 즉, c*n/4 - c/2 - a*n >= 0 임을 보여야한다. 이 식을 정리하면 다음과 같다.
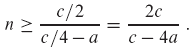
따라서 n < 2*c/(c-4*a)에 대해 T(n) = O(1) 이라고 가정하면, E[T(n)] = O(n)이 나온다. 따라서 선형 시간에 순서 통계량을 찾을 수 있다.
3) Selection in worst-case linear time
이제 최악의 경우 실행 시간이 O(n)인 선택 알고리즘을 보자. RANDOMIZED-SELECT와 마찬가지로 SELECT 알고리즘은 입력 배열을 재귀적으로 분할해 원하는 요소를 찾는다. 그러나 여기서는 배열을 분할 할 때 양호한 분할을 보장한다. SELECT는 퀵 정렬의 결정적 파티셔닝 알고리즘 PARTITION을 사용하지만 요소를 입력 매개 변수로 파티셔닝하도록 수정했다.
SELECT 알고리즘은 다음 단계를 실행해 n > 1개의 개별 요소로 구성된 입력 배열 중 가장 작은 것을 결정한다. (n = 1인 경우 SELECT는 입력 값을 i번째로 작을 값만 반환한다.)
- 입력 배열의 n개의 요소를 각각 5개의 요소로 구성된 ⌊n/5⌋개의 그룹과 나머지 n개의 mod 5 요소로 구성된 최대 하나의 그룹으로 나눈다.
- 각 그룹의 요소를 먼저 삽입 정렬 (최대 5개) 한 다음 정렬된 그룹 요소 목록에서 중간값을 선택해 각 ⌈n/5⌉ 그룹의 중앙값을 찾아라.
- SELECT를 재귀적으로 사용해 2단계에서 찾은 ⌈n/5⌉ 중앙값의 중앙값 x를 찾아라. (짝수의 중앙값이 있는 경우 규칙에 따라 x는 하단 중앙값이다.)
- 수정된 PARTITION 버전을 사용해 중앙값 x의 입력 배열을 분할해라. k는 파티션의 아래쪽에 있는 요소의 수보다 하나 이상이 되도록해 x는 k번째로 가장 작은 요소이고, n은 k에 해당한다.
- i = k 이면 x를 반환한다. 그렇지 않으면 SELECT를 재귀적으로 사용해 i < k인 경우 낮은 쪽에서 i번째로 작은 요소를 찾거나, i > k 인 경우 높은 쪽에서 가장 작은 i번째 요소를 찾는다.
SELECT의 실행 시간을 분석하기 위해 먼저 파티셔닝 요소 x보다 큰 요소 수의 하한을 결정한다. 그림 9.1은 이 bookkeeping을 시각화하는데 도움이 된다. 단계 2에서 발견된 중앙값의 적어도 절반은 중앙값 x 이상이다.
 그림 9.1
그림 9.1
위 그림을 보자. 각 요소는 작은 원으로 표시되고, 5개 요소로 구성된 각 집단은 하나의 열로 이루어진다. 집단의 중앙값은 흰색으로 칠해지고, x는 따로 표시되어 있다. 화살은 큰 요소에서 작은 요소로 향해 간다. x의 오른쪽에 있는 각 그룹의 요소 3개는 x보다 크고, x의 왼쪽에 있는 각 그룹의 요소 3개는 x보다 작다. x보다 큰 요소는 그림에서 회색 배경으로 나타나 있다.
따라서, ⌈n/5⌉ 그룹의 적어도 절반은 x가 n을 정확하게 나누지 않는 경우 5개보다 적은 요소를 갖는 하나의 그룹과 x 자체를 포함하는 하나의 그룹을 제외하고 x보다 큰 3개 이상의 요소를 기여한다. 이 두 그룹을 빼면 x보다 큰 요소의 수는 최소한
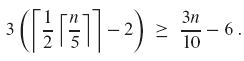
유사하게, 3n/10 - 6 이상의 원소는 x보다 작다. 따라서 최악의 경우 5단계는 최대 7n/10 + 6 요소에서 SELECT를 재귀적으로 호출한다.
이제 알고리즘 SELECT의 최악의 실행 시간 T(n)에 대한 반복을 개발할 수 있다. 1,2,4단계는 O(n) 시간이 걸린다.
(2단계는 크기 O(1) 세트에 대한 삽입 정렬의 O(n) 호출로 구성됨)
단계 3은 T가 단조 증가한다고 가정 할 때 T ((n / 5⌉)의 시간이 걸리고, 5단계는 최대 T(7n/10 + 6)의 시간이 걸린다. 140개보다 적은 요소를 입력하려면 O(1) 시간이 필요하다고 가정한다. magic 상수 140의 기원은 곧 명확해 질 것이다. 따라서 우리는 다음 식을 얻을 수 있다.
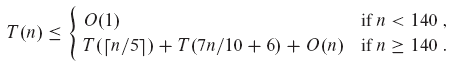
우리는 실행 시간이 치환을 통해 선형임을 보여준다. 보다 구체적으로, 우리는 적당히 큰 상수 c에 대해 T(n) <= cn이고, 모든 n > 0임을 보여줄 것이다. 우리는 적당히 큰 상수 c에 대해 T(n) <= cn이고, n < 140 이라고 가정하고 시작한다.
c가 충분히 크면 가정이 유지된다. 또한, 위의 O(n) 항에 의해 설명된 함수가 모두 n > 0 에 대해 위에 묶여있는 상수를 선택한다. 이 귀납 가설을 반복 right-hand 대입하면 다음 식이 산출된다.
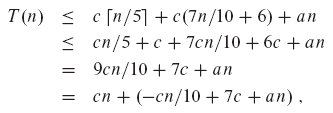
위 식은 다음 식을 만족하면 최대 cn이다.
-cn/10 + 7c + an <= 0 (9.2)
n > 70일 때, 식 (9.2)는 c >= 10a(n/(n-70))과 동치이다. n >= 140이라고 가정했기 때문에 n/(n-70) <= 2이고, c >= 20a는 부등식 (9.2)를 만족한다. 따라서 SELECT의 알고리즘의 최악인 경우 실행 시간은 선형적이다.
- 정리 : sorting & indexing으로 SELECT 문제를 해결하려고 하는 것은 점근적이므로 비효율적이다.
Leave a comment